Making a reliable public transit chatbot: don't trust your assumptions
Around a year ago, I made a Discord bot to provide live public transit schedules for the students of my university. Creating a prototype was easy, but making it reliably output accurate schedule data required more consideration than expected.
The bot is simple: it takes a station name as input and outputs the next stop times for trams and buses serving it. On the surface, this looks relatively simple, but it quickly gets more complex when we realize there exist many edge cases we didn’t consider at first. These unusual cases take the most significant portion of our development time.
This post exposes some of the challenges encountered along the way.
The basics
Let’s build the bot! To get started, we need to look at how to obtain the data we need.
CTS, the local public transport company, publishes its data through two channels: downloadable file archives that follow the GTFS format and a REST API in the SIRI format.
The GTFS files contain theoretical schedules. Real-time schedules are obtained using the REST API. Some data, such as the list of all the network’s stops, is available in both channels.
From a quick look at the stops.txt CSV file from the GTFS archive, we can see stop names are always present at least twice in the data, sometimes more:
stop_id,stop_code,stop_lat,stop_lon,stop_name,...
...
HOFER_04,275C,48.5843508842,7.7449911833,Homme de Fer,
HOFER_05,275D,48.5843863707,7.7446827292,Homme de Fer,
HOFER_13,275A,48.5839729513,7.7446076274,Homme de Fer,
HOFER_14,275B,48.5841308672,7.7445673943,Homme de Fer,
...
This is expected because stops aren’t the same as stations: stops are the specific places within a station where trams and buses stop. For instance, you would typically have one stop for each side of the road in a bus station. There can be even more stops when additional directions or transport modes are involved, so it makes sense that all the stops from a particular station share the same name.
The image below shows the Homme de Fer station and two of its four stops:
 |
|---|
| Original photo by Ex13, CC BY-SA 2.5, via Wikimedia Commons |
{kind=link}
Reading the REST API documentation, we can see it has an endpoint that can take a list of stop IDs and return their schedules.
With all of this in mind, here is what we want to do when we a user sends us a request:
- Find all stops that belong to the requested station
- Call the public transit company API with the selected stops
- Format and output the result to the user
So we go ahead and code it. Without any significant roadblock, we get to the point where we can output something like the following to our users:
Schedule for Observatoire:
Trams 🚊:
C: Gare Centrale: 6 min, 18 min, 28 min
C: Neuhof R.Reuss: 1 min, 11 min, 21 min
C: Gravière: 66 min
E: Robertsau - L'Escale: 3 min, 13 min, 23 min
E: Campus d'Illkirch: 7 min, 17 min, 27 min
F: Comtes: 3 min, 15 min, 27 min
F: Place d'Islande: 5 min, 15 min, 25 min
Buses 🚌:
2: Elmerforst: 17 min, 44 min, 69 min
2: Jardin des Deux Rives: 13 min, 32 min, 49 min
L1: Lingolsheim Alouettes: 18 min, 39 min, 67 min
L1: Robertsau Lamproie: 2 min, 23 min, 43 min
After testing the bot with many stations and getting satisfying results, we start to be more and more confident that we are mostly done, but reality quickly strikes back when we find our first buggy station.
Missing directions
While testing requests for a station, we find something that doesn’t look right: the next stop times are present for one direction but are missing for the other.
B: Lingolsheim Tiergaertel: 5 min, 12 min, 21 min // Cool...
// ...but where is "B: Elseau"?
After a manual review of the data, we find that the affected stops all have slight inconsistencies in their names, for instance, accent differences such as in Ostwald Hôtel de Ville vs. Ostwald Hotel de Ville, casing differences like Lipsheim gare vs. Lipsheim Gare and even others such as varying number of whitespaces.
This causes some directions to be missing because, in our implementation, we first search for the station name that best matches the user’s request, then use it as a key to retrieve all its stop IDs from the stops.txt file and finally use them to make our API request. The problem is that this is assuming all stops that belong to a certain station also precisely share the same name, but with these slight differences, we cannot directly use a single key anymore; otherwise, we won’t be requesting the data for all stops, and some directions and lanes will be missing.
A solution to fix this is to normalize the names by doing the following:
- Remove accents, special characters, whitespaces, and repeated letters
- Lowercase all characters
This way, Ostwald Hôtel de Ville and Ostwald Hotel de Ville both become ostwaldhoteldevile.
Now we can use the normalized names and get all the stops of our stations. Since we also normalize the user input, we can now autocorrect many small typos they make.
| I must point out that this method is a bit brittle: it won’t work in the case of more significant inconsistencies. It could also confuse different stations if the differences in their name were so minor that normalization removed them. Let’s see this as an intermediary step that will make more sense once combined with other techniques mentioned below. |
Erroneous stops
After a bit more testing, we find a new problematic station: while our previous issue was that some schedules had missing data, this one is the opposite: the schedule contains additional lanes that don’t belong to the station.
Once again, we manually review the corresponding data and find an intruder among the affected station’s stops: contrary to the normal ones whose IDs all contain parts of their station names followed by a number (such as PARLE_01), this one only has a single number: 999.
We search the stops.txt file to see if it would be present elsewhere and find it in other places too, which is one more confirmation that something is wrong. A direct call to the API with this ID also confirms it returns invalid data.
What should we do now? Filter out stations that contain this ID? What if other invalid ones were to appear?
At this point, we start to wonder if using the GTFS file was the correct choice. We remember something we saw from the REST API docs: instead of passing stops IDs to retrieve schedules, it is possible to give a single station ID (also called “logical stop code” in the docs). Our issue is that the GTFS file contains no such ID (which is why we used the stop IDs up until right now), but we notice the API does have a stop point discovery method that should provide us with a list of stops that store both their stop ID and their parent station ID.
After some tests, we realize that calling the schedule API endpoint with a station’s ID (instead of all its stops IDs) returns us clean data. Great! No more trace of the 999 stop!
From now on, we will stop using the GTFS files and only use the API endpoints, which seem to help us get more accurate data.
Missing directions, the comeback
Happy with our new solution, we continue testing our bot and find an issue we thought we had fixed before: a station where some lane directions are missing.
Previously, we had issues with inconsistent station names; now, a variation of this issue has come back for us: inconsistent station IDs!
After a closer look at the stops of a station exhibiting this issue, we realize that while their names are consistent, they don’t all share the same station ID! This makes it look like they belong to different stations, but they don’t. Contrary to what we expected, a single station can have more than one ID because it may have been split erroneously in the database! This also means API requests using a single ID will only return partial data and explains why some directions are missing again.
To fix this, we retrieve all the IDs of the requested station (similar to what we used to do with stop IDs) and use them to get schedules that we then merge to return complete data to our users.
Station names are not always unique
Since the bot gets its data from a single local public transit company, it might not have initially occurred to us that there could be name collisions between stations. This is a rare occurrence, but there are two stations named “Perdrix” that are 20 kilometers away from each other.
If a user requests the schedule for such a station, we must let them know multiple ones correspond to the name they typed. When we find two stations with the same name, we reverse geocode their geographical coordinates to find their respective cities and postcodes, which we then append to their names, for instance:
- Perdrix (67550 Vendenheim)
- Perdrix (67115 Plobsheim)
This way, the user knows which station is which in the menu we present them.
Merging strategy
From what we have seen so far, there are two cases of station name duplication: different stations bearing the same name and single stations that were erroneously split in the public transit company database. When the API provides us with stations that share the same name, we do the following:
- If they are physically close, they must be parts of a single station that has been wrongly split, so we merge them.
- If they are far away, they must be truly distinct stations, so we distinguish them with their addresses and don’t merge them.
This approach has worked great so far, but there is a third case we haven’t encountered yet!
Meet the “Ile de France” stations
The “Ile de France” stations are two stations that have the same name and are close to each other, which at first glance looks exactly like any other case of erroneous data we already know to correct. Still, there is a difference we can see from taking a look at this official map:
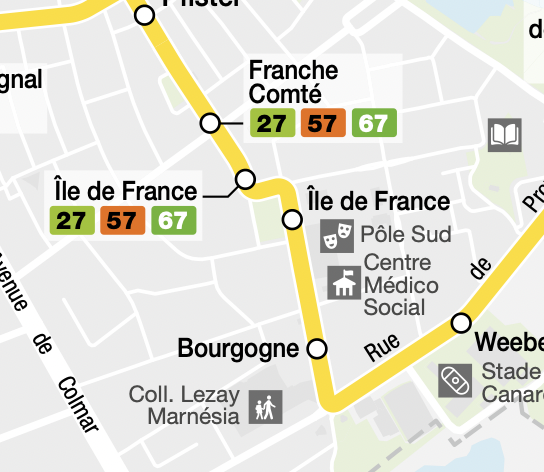 |
|---|
| Screenshot of the bus lane 40 schedule map © Compagnie des Transports Strasbourgeois — Map background © OSM |
There are two distinct “Ile de France” stations along bus lane 40! They are close to each other, but we can’t merge them!
Now we need a strategy to differentiate this station from the erroneous ones. One way is to detect if two neighboring stations we would like to merge contain stops for the same lane/direction pair (for instance, “lane 40 in the direction of Neuhof Ganzau”). If they do, we know it doesn’t make sense because a station shouldn’t have two redundant stops, so we conclude these stops must belong to separate stations we shouldn’t merge.
| Think about how weird this is: the buses make their first stop at “Ile de France” and then continue their route towards the next station… the other “Ile de France”. I found it hard to believe, so I did some research and was able to confirm that this really is what’s happening. This is such a peculiar case that I am considering doing this differently in the future: we might as well add special handling for stations like this one instead of implementing a more general solution based on assumptions that might not be true anymore if new errors were to occur in the database. |
Interpreting users’ requests
Users can’t always know and type exact station names when sending their requests. Therefore, we implement fuzzy searching to find stations whose name is close to the user input, and then we make them select the exact station they want. We also wish to provide results immediately if we have a station exactly matching a user’s request. Here is how we might do this:
if (exactMatch(request)) {
// Return results straight away
} else {
// Do a fuzzy search and ask the user to select a station
}
Suppose a user is looking for information about the “Place of Romans” station; they could make a mistake and only type “Romans”. Based on the code snippet above, we could expect the algorithm to take the second execution path and do a fuzzy search since this isn’t an exact match. However, that’s not what happens because there actually is an exact match: the “Romans” station!
There are three stations whose name contains “Romans”:
- Romans
- Place of Romans
- Parc of Romans
If we don’t pay attention, the first one could be matched by requests intended for the other two without the users noticing! To add to the confusion, these three stations are placed along the same bus lane: we would be providing the expected lanes but with the wrong stop times.
We can easily fix this by always doing a fuzzy search — even if an exact match exists — and then determining if there are stations whose names would be too close to what was requested. In this case, the exact match isn’t used directly, and we instead ask the user to select a station among the possible choices.
Other issues
For the sake of completeness, here are some more issues we won’t have time to cover in this post:
- Duplicated stops
- Stops with inaccurate geographical coordinates
- API returning incoherent data in the middle of the night
Thankfully, with correct API usage and minor code adjustments, it is easy to avoid being too much affected by those.
We finally did it! No more bugs, at least for now…
The transport company welcomes feedback from API users. Many issues cited in this post have been resolved on their side for some time now.
Seeing a well-designed, nicely structured API, I almost forgot it didn’t guarantee anything about the accuracy of the returned data. Encountering so many issues caused by invalid data was surprising, and it made me realize that sanitizing users’ input alone often won’t be enough.
Other times, there was nothing wrong with the data, but I still had to reconsider my initial approach to provide a better user experience.
I am glad this project turned out to be more challenging than I expected. The issues were frustrating initially, but finding their cause, fixing them, and learning from them made for a very positive experience.